I’ve moved to the greener pastures of LowlyMath.net! Come visit.
Note on formatting
Turns out the import of posts from the blogger account didn’t go all too smoothly, alot of the formatting was lost in the translation. If you’d like me to fix up any particular post, I’ll be sure to get to it, but there are quite a few, so unless I’m asked, I don’t intend to fix them right away, (I’m a bit strapped for time right now, working on some school extra credit stuff). Hopefully I’ll get caught up on it. Note though, that the text itself is fine, just the formatting tags (pre and code tags, specifically) are being interpreted as text, and not markup. So if you copy and paste it (if its a literate haskell file, for instance) it should still work (and even look okay, maybe).
Sorry,
~~Joe
Monkey Multiplication Table Problem
This is a response to R. Andrews post here. I have dubbed it, “The Monkey Multiplication Problem.” it was fairly neat, and I was going to post a response in the comments of his LJ, but I didn’t want to bother to sign up for an account over there, so instead I’ll post it here.
Enjoy. And forgive the lack of comments.
I managed to do it in 9 lines of haskell (not including module, import, or type declarations) however, I don’t have any datasets larger than your 12×12 table to test against, the printout is kind of funny looking, it’s designed so that you turn it 45 or so degrees clockwise and it looks right, (comes from the fact that I generate it by columns)
code follows (17 lines, with spaces and extra decls)
module Table where
import Data.List
genTable :: Int -> [[((Int, Int), Int)]]
genTable max = map (genCol max) [1..max]
genCol :: Int -> Int -> [((Int, Int), Int)]
genCol max n = [((n,n), n*n)]
++ zip z (map (\(x,y) -> x*y) z)
where z = zip [max, max - 1 .. n + 1] (repeat n)
printTable :: Show a => [[a]] -> IO ()
printTable = putStrLn
$ concat
$ intersperse "\n"
$ map (concatMap (\x -> show x ++ " "))
monkeyTable = printTable $ map (map (snd)) $ transpose $ genTable 12
You can load that up in ghci and type in “monkeyTable” to get the printout, printTable, btw, is general enough to apply to anything- so if you’d like to see the internal structure of the table, you can switch that “map (map (snd))” to “map (map (fst))”. note that the ugliness of the monkeyTable function is from the fact that I used tuples instead of a customized datatype, or just a more specific genCol function.
Anywho, fun problem, I think I might use it in my local coding dojo, have fun!
~~jfredett
On Raytracers, The Quantum Kind
Well, maybe not quantum — but wavestream based light ray tracing software didn’t have the same, y’know, ring to it. Let me give you the backstory.
This semester I’m taking one of my requisite natural science classes, In trying
to find a class which looked the least boring, I managed to find an Optics class. In Optics, we learn about the dual nature of light, a subject which has always fascinated me. In much of mathematics and physics, there is an inherent duality, a separation between two objects which simultaneously brings them together. When you get to Optics, we find that light- in on of the weirdest twists ever – manages do be its own dual, separate from itself, if you will. Light, as we (maybe) well know, has both wave-like and particle-like properties. My Optics Professor calls it the “Packet of Wiggling String” interpretation. This interpretation helps to explain things like the double slit experiment. It is this particular experiment that I want to talk about now.
I’ve fiddled with ray tracers before in my life, but I’ve never thought to try the double slit experiment in one of them, I cooked up a little pov-ray script to test my theory that, in fact, ray tracing is classical. Granted thats an obvious result to most, but think about it, raytracing is classical. You can’t replicate the double slit experiment in Povray, more accurately, you can’t treat light as a wave in Povray. only as a particle stream.[1] As far as I can tell, this gross approximation of light– limited reflection calculation, particle stream vs wave, etc — was based on limitations of hardware when the technique was invented, they simply _couldn’t_ simulate things like the Double slit experiment. Perhaps more surprisingly, Prism’s don’t work the way they should either, since they won’t separate light based on wavelength.
NOTE:: As an aside, probably the most fascinating thing we have learned in optics so far is how prisms separate light into its component colors. I thought a short description might pique your interest, so here you have it.
When light travels through certain substances (usual called media (singular medium)), it slows down and actually bends due to a phenomenon called refraction. Refraction is really just an application of Fermat’s Principle (that light will always take the fastest path between two points[2]). The easiest way to see refraction is by looking through a magnifying glass, a magnifying glass is a medium made of glass, which has a special, dimensionless number called an “index of refraction” at around 1.5, air has a IOR of about 1, and a vacuum (like space, not like a hoover) has a IOR of exactly 1, there is no substance with an IOR
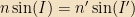
where n, n’ are the IOR’s of the two media (n being the IOR of the medium from which the light originated.)
and I,I’ the angles at which the light (or lifeguard) “impacts” the medium
This equation, called Snell’s Law (not snail, snell, it rhymes with “sell”), gives us a simple way to solve the lifeguard problem. By knowing the distances from shore both we, and the victim are[5] we can determine a shortest path using some trigonometry, which I’ll leave as an exercise to the reader, since I don’t have any good visualization software to draw all the necessary pictures (xpaint will _not_ be sufficient, and the 15 minute time limit on Cinderella2 is beyond
annoying.) Regardless, this is the same math that governs refraction, however, there is something I have not explained.
n is not a constant.
This shook my soul, at first, how can n not be a constant? If we have one uniform material, we assume no inconsistencies in the material when we do our math- the only possible thing it could depend on would be light itself, but if light is a uniform particle stream then this couldn’t be the case.
Shocking revelation number two, light isn’t a particle stream.
Refraction works on a particle stream, it makes _sense_ on a particle stream, in fact, the very reason for refraction really doesn’t make sense on a standing wave- because how can a infinitely long wave slow down? Thats just silly. So really, this whole refraction business leads us to a more quantum interpretation, but for simplicity, we’ll pretend it all works with waves.
n is a function of the wavelength of the light approaching the medium, this is important, because it tells us something interesting about light. Consider the prism, we all have seen how the prism can split apart light in an amazing display of party trickery into all its very pretty colors. Prism’s truly are the life of the optical party, useful for all sorts of stuff, from periscopes to spectrometers. In any case, how can a prism split white light into a bunch of different wavelengths? We can’t create something out of nothing, so we are left with only one explaination, white light _is_ all of the component colors. This leads us to see that really- when we see white light, we are seeing the superposition of many different wavelengths of light, and this gives us why a prism works. If n is just a function of wavelength, and white light is a superposition of different wavelengths, then each wavelength will bend more or less depending on _its_ own value for n, this means that when the light exits the prism, due to it’s shape[6], it will remain separated, and create a beautiful collage of colorfulness on whatever the light happens to land on.
So, enough rambling about Optics, what has all this got to do with raytracing? Well, I realized that you can’t build a prism in a raytracer, because it treats its light not only as a simple particle stream, but also as having a unique wavelength (of sorts) for each of its colors. In Povray, you specify color as a vector, nothing special, just a vector. Why not treat color as a series of wavelengths? Heck, we don’t even need to give up our lovely RGB method, theres
very likely a way to convert from wavelengths to RGB and back. We would have a problem with the way Raytracers currently treat light and color, since we say that objects and light _have_ color, when in reality light is usually white, and the things it touches _absorb_ color and have some amount of transparency, which gives the illusion of colored light. Potentially we could specify the color of light which is emitted and the color(s) of light which are absorbed by the surfaces we create- but the latter of that bit might be more difficult. This is besides the point[7]. I suppose what I am suggesting is that we consider ways to incorporate the wave nature of light into our raytracers, since we could potentially add quite a bit of very interesting new capabilities, like prisms, interference effects, etc. It would also add to the wonderful photorealism effects, I think, since the light would be specified in a way that is more like
reality.
Just thoughts, I suppose, I’m certainly no expert in Raytracing. However, oh dear Lazyintarweb, if you are, please- tell me whether this could actually work, maybe I’ll try to build it, someday.
[1] In fact, only as a particle. Since we only view the ray’s reflections once.
[2] In reality, the principle is stated (mostly) as follows: Light will always
seek the path which minimizes its travel time. There is a subtle difference, but I think for our purposes, the simpler statement suffices. Also note that fastest doesn’t necessarily mean shortest, since we’re dealing with speed changes too.
[3] I don’t think I’m wrong, but maybe exotic substances or whatever creates wormhole things might? I’m not sure how that works, I’m just a mathematician who likes pretty lightshows, not a physicist.
[4] Yes, I know there is the whole non-euclidean geometry of space thing, geodesics and whatnot, but bear with me.
[5] I never realized lifeguarding was such a deep realm of math.
[6] Namely, the triangluar shape of the classic prism prevents the light from bending back towards the normal, and reforming the normal white light. A thoroughly less satisfying party trick, to be sure.
[7] In fact, at this point, I have practically forgotten what the point was.
Why Testing code should be Laissez-faire
I’ve been working on the HFA Library some more, and got to the point now were I really want to start testing it deeply. Since HFA is in Haskell, the weapon of choice for testing pure code is QuickCheck. The interesting bit about QC is that test data is fundamental random. This is great for two reasons.
1) It forces you to actually test for _general_ properties of objects/functions, rather than specific properties of certain instances of those structures, like a unit test does
2) By Generating Random Data, you don’t have to worry about being too nice or too mean to your program, as with unit testing.
I’ll state it now, for the record, Unit Testing is great. I wouldn’t test my Java (or soon enough, Scala, ^_^) programs with (mostly) anything else. However, when you have referential transparency on your side, QuickCheck is a superior system.
The real brilliance of QuickCheck though, is that it is extensible enough that you can define new “checkable” items, that is, instead of having to use the standard checkable types when checking a function, you can define how QuickCheck can generate random data for a particular type by making it an instance of the Arbitrary class, which is defined by QuickCheck. This means that, as long as you can define a couple of methods for your datatype, it is damn near trivial to have QC generate examples of your datatype and test them quickly.
Why is this good? Well, consider you’re writing unit tests for your code. You’ve been intimately involved with this mangled peice of imperatively worded text for days and weeks. You know every inch of it, and you have in your mind the next new feature you want to add. It is not uncommon (at least for me) to begin writing and toying with the code in your mind, figuring out where potential bugs might be. As a human being, you are typically not looking to make things harder for yourself than needbe. So maybe, when you’re writing those unit-tests that will guide your programming to ensure that the code is written correctly, you — maybe subconciously, maybe not — decide to make those few unit tests a little bit easier on the part of the code that you think is more fragile. I’m guilty of this, certainly, and I’m sure if you’re honest with yourself and you’ve developed a good bit of code with the test-first methodology (which I like only mildly less than the test-shortly-after-you-realize-you’re-supposed-to-write-tests-first methodology), that you would find that you’ve done it too. QuickCheck fixes that wagon pretty quickly, you don’t get to reason about how hard some tests will be on the code, QuickCheck enforces a “Hands Off” or “Laissez-faire” (I’m french, and I like history, sue me.) form of testing. You don’t get to decide what is tested, just what the result should be, which is how it _should_ be done. I _shouldn’t_ be thinking about what data I want to test, I shouldn’t have to write all the test-data, ideally, I should only have to say, “minimizing a DFA twice is equivalent to minimizing a DFA once” or “if the regular expression foo is generated by DFA f, and the expression foo’ is generated by the minimized version of f, then foo == foo’ for all f::DFA.” I guess the point is, the computer is unbiased, it won’t be nice to the code, it won’t be mean to it, it’ll be fair. Is that to say that coders will be biased towards or against their code? Yes, it is, we spend alot of time with these projects, we develop a vested interest in seeing them work, finding out that you did something wrong can be discouraging. Granted, small things may not devastate you, like using the wrong function name, or misplacing a variable. But if you’re unit test catches a major flaw in the structure of a program you designed, that represents alot of work that just got blown to peices. At the very least, if not for your pride, testing systems like QC are good for your productivity, they allow you to test a (potentially) huge number of arbitrary cases every time you run your program. Heck, you could even have QC running live against your code in the background, telling you in real time what tests your failing, what cases gave you failures, etc. All of that is Automatic and Vital data, its 24/7/365 testing of your code, for free. Slowly building assurance that your code is, in fact, doing the right thing on all inputs.
By the way, Yes, I know many, many people have written about QuickCheck before, and about how wonderful it is, but I think it’s always worth saying again. Good Ideas deserve to be talked about, QuickCheck is a _very_ good idea.
DFAs, Categories, and Typecheckers.
I’ve recently started reading (in parallel) “Type and Programming Languages” and “Basic Category for Computer Scientists.” The latter of which is really only interesting if you’re a math junky, like me. It’s somewhat dry, and very matter-of-fact, but the subject is terribly interesting.
Whilst reading these books, I’ve also been working on a library for Haskell called “HFA” (pronounced: “Huffa”, or if your feeling silly, “Hoffa”), for “Haskell Finite Automata.” The library’s purpose is to create a simple to use, generic, relatively fast implementation of various Automata (Notably (D|N)FA’s, PDAs, Turing Machines, etc.), so that anyone intending to use these abstractions will be able to without knowing much about the internal theory, eg how to minimize a DFA, or how to convert an NFA to a DFA, etc. It’s also intended to be available as a easy to understand tool for learning/teaching about automata, it will eventually have the ability to display Automata as Graphviz graphs, and is currently capable of generating state diagrams (with some extensions to mark final, initial, and initial-final states).
Recently, I had just finished writing some refactor code for HFA, and decided to take a break and read “Basic Category Theory” for a while, it dawned on me upon looking at the diagram of a category that what I was looking at was essentially a DFA, with all states final, and the arrows between them being processing parts of the Delta Functions. That is, if a Category is defined as a a set of objects, and a set of arrows (where an arrow is defined as f : A -> B, where A and B are objects in the category), then the equivalency is as follows:
Category DFA
Objects States
Arrows Transitions
with delta(S,x) = S' iff there is an arrow between x is an arrow between S and S’.
Notably, we can also define a DFA as a Category by simply reversing the definition. I’m pretty sure this fact has been discovered before, its to obvious to believe otherwise (though it would be cool I could name this “The Fredette Isomorphism”, ^_^). The interesting thing about this Isomorphism is that, if we can generalize a DFA, whats to say that we couldn’t generalize the category in the same way? Take Imperative languages for instance. I don’t know if it works out (and I certainly don’t have the skill to prove it if it does work out, at least not yet), but it is a hypuothesis of mine that an imperative program can be represented in a category with multiple arrows going from one object to another simultaneously, that is, an imperative program is a kind of “Nondeterministic” category. Ring any bells? We know (by the simple fact of Turing completeness) that a TC imperative language program can be written in a TC Pure Functional language (assuming there’s a Pure Functional way to deal with State, eg Monads). Similarly (and this is almost to much of a guess to even _think_ of it as a hypothesis) if a TC Imperative Language is a “Nondeterministic” (ND) category, then if a ND Category is isomorphic to a NFA, then we know that NFA’s are isomorphic to DFA’s, and we know that Pure Functional Languages are isomorphic to operations withing a “Deterministic” Category, eg a “DFA”, so that would “prove” (I use that term _very_ loosely) that any old TC Imperative program has an equivalent TC Pure Functional Program.
Pretty Neat, huh? It probably doesn’t work somewhere, but still- it’s cool.
We can further use the DFACategory relationship as a kind of simple “composition” checker.
If the States of our DFA are types in a language, and the transitions functions mapping one type to another, then we can say that if the delta function is defined as above, and in the case there is no defined transition between some state S and some other state S’, and if such a transition is called for in the delta function, then we simply send the output to a non-accepting “fail” state.
Here, the simple language consists of the following.
The Category contains:
Objects = {Int, Float, Char, Bool, Unit}
Arrows = {isZero :: Int -> Bool,
,ord :: Char -> Int
,asc :: Int -> Char
,sin :: Float -> Float
,not :: Bool -> Bool}
Values = {zero :: Int, true :: Bool,
,false :: Bool, unit :: Unit}
The corresponding DFA works something like this
f1,f2, ... fn are symbols which have type an -> bn,
where n is the same value as the nth symbol, and a and b are not type variables, eg: f1 :: Int -> Char, a1 = Int, b1 = Char
v is a type
(f1 . f2 . f3 . ... . fn) v
=> ([f1, f2, ..., fn], v)
=> [a1,b1,a2,b2, ..., an,bn,v]
=> [(init,a1),(b1,a2),(b2,a3),...,(bn,v)]
given this list of pairs, we define the DFA trace function as follows, this presumes a list like the one from above.
trace :: State -> [(Sym,Sym)] -> Bool
trace st [] = (st /= failState)
trace st [(s1,s2):syms]
| s1 /= s2 = False
| otherwise = trace (delta st (head syms)) syms
where failState is a pseudonym for whatever the magic non-accepting failure state is
and where delta simply points to the next state (be it the fail state, or otherwise). I’ll cover that in more detail in my next post (I’m actually going to build this little guy for a simple language like the one above.)
I’ve digressed a bit from my topic, my goal was to show that Categories are really terribly neat, and apparently related to automata, which most people understand pretty easily, if they are explained well. I don’t pretend to be an authority here, but hell, implementing a (very) simple type checker is a pretty cool feat, considering It was only a few months ago I started learning Haskell. I know that this isn’t a robust, powerful mechanism, but as far as I know, given Compose (the (.) function in Haskell) apply (($) in Haskell) and a few other functions, you have a TC language, a la Backus’ FP or FL systems.
Anyway, next time I intend to implement this little type checker, and (hopefully) eventually implement a (full) type checker for something akin to FP or FL, using this DFA style approach. Heck, I’d also be able to play with parsing (another automata rich subject).
Also, for those interesting in looking at HFA, it’s available at
http://code.haskell.org/HFA/testing
you can just do a darcs get to pull everything down.
###DISCLAIMER###
I don’t intend to present any of this as proven, either formally or by any other means, the ideas and conjectures in this post are just that, conjectures. Please, don’t believe I’m an expert, I’m still learning about all these things, and I don’t want to lead anyone down the wrong paths under the assumption I actually _know_ what I’m doing.
That said, I do think the conjectures made have some validity, if you know otherwise, please inform me. Thanks
~~Joe
Peano’s Axioms IV: Advanced Functions and Integers
So here’s the last installment, we’ll make use of all the infrastructure we’ve build up to define primality, and associated functions like, a divisor function, totient, and sigma and whatever else I can come up with.
as always this is a literate source, save to Peano3.lhs and make sure you have the previous posts, execute with:
ghci Peano3.lhs
and have fun.
No big preambles this time, Lets go.
module Peano3 where> import Peano2> import Data.List
First, all this stuff will boil down to prime numbers. So lets come up with a way to test if a number is prime or not.
An easy method is to create a seive of all prime numbers, then our isPrime function is just a search on the list, is it the fastest method in the world? Not really, does it work? You bet it does.
> natPrimes :: [Nat] natPrimes = sieve [S(S(Z))..] > sieve :: [Nat] -> [Nat] -> sieve [] = [] > sieve (x:xs) = x : sieve [y | y -> xs, y `mod` x /= 0]
Awesome, we all know about Haskell’s powerful List Comprehensions. Now lets implement that simple linear search on the list.
> isPrime :: Nat -> Bool > isPrime x = isPrime' x natPrimes > where > isPrime' x (p:ps) > | (p | otherwise = (p == x)
EDIT: augustss mentioned that my use of seq was pointless, theoretically, it would be more efficient to use strict evaluation here, but it won’t till I learn how to do that. It’s unfortunate ghc/hugs won’t recognize tail-recursion and make it strict automatically ![]()
Cool, all we’re doing here is building up a chain of “does element p_k equal the given number?
Now what? Well, since we’ve defined prime numbers over the naturals, we can do some handy things like create a factorization function. We’ll just use trial division to determine the factors
> factorize :: Nat -> [Nat]> factorize x > -- if the number is prime, we're done. > | isPrime x = [x] > -- if not, then we know we just need to find the first > -- factor, and then recurse on the number `div` the factor > | otherwise = firstFactor > : (factorize (x `div` firstFactor)) > where > divides x y = (y `mod` x) == 0 > firstFactor = head > $ dropWhile (\p -> not (p `divides` x)) natPrimes
Fast? Hell no, it takes quite some time to factorize 210, and I didn’t even bother to wait till it finished 2310, but it does work.
We know we can create a generic “closure” function, which takes a list and a operation on the elements of that list and recursively applies that function till the list is “closed” that is, applying closure again returns the same list. Lets write that quickly.
> closure :: Ord a => (a -> a -> a) -> [a] -> [a] > closure f ls = closure' f ls [] > -- closure' is just a helper function which keeps track of the > -- last list for comparasion against the closed list > closure' :: Ord a => (a -> a -> a) -> [a] -> [a] -> [a] > closure' f ls old > -- if the old list is the same as the new list, return the > -- list > | ls == old = sort ls > | otherwise = closure' f (performClosure f ls) ls > performClosure :: Eq a => (a -> a -> a) -> [a] -> [a] > performClosure _ [] = []> performClosure f (x:xs) = [x] > `union` (map (f x) xs) > `union` (performClosure f xs)
Well, okay- it wasn’t that simple. However, using this, we can write the “divisors” function, which returns a set of all numbers which divide a given number. We’re going to use a nifty trick here too, I’ll take a moment to explain it.
Normally, we see closed sets defined with a “mod” function, as in the group of integers mod 10, etc. We can define the closure operation (in Haskell’s lambda notation) as being:
\ x y -> (x + y) `mod` k
for some constant k. However, this really doesn’t work well when trying to come up with a closure operator for divisors. What we need is a function which will dynamicly limit the power to which each factor is raised. Fortunately, a nice mathematician named Euclid came up with a handy algorithm for creating a function just like this, it is called the greatest common divisor, the GCD.
Upon examination, you’ll note that the function:
\ x y -> (x * y) `gcd` k
will force the product to only contain appropriately sized factors, because if the multiplication creates a number with an factor with an exponent greater than that of the same factor in k, then it will simply return the factor to the lower of the two powers.
So now, lets create a divisors function based on that concept and previously defined functions, we need to add 1 to the list because our factorization function won’t return that.
> divisors :: Nat -> [Nat]> divisors k = S(Z) : closure closer (factorize k) > where closer x y = (x*y) `gcd` k
Pretty simple, just one more reason to love Haskell. Lets define sigma, which is the sum of divisors to a power function. That is
> sigma :: Nat -> Nat -> Nat > sigma k p = sum (map (^p) (divisors k))
Hmm, lets do one more big one, how about Totient, that is, the total number of all numbers x less than k that satisfy the property gcd(x,k) == 1
> totient :: Nat -> [Nat] > totient k = length [x | x <- [S(Z)..(k-1)], gcd x k == 1]
List comprehensions are awesome, aren’t they?
Okay, last thing on our list, Integers. So far, we’ve been dealing with Naturals so far, and as such, have not had negative numbers to deal with. What I intend create a “Smart” Datatype which can cleverly increment and decrement without much difficulty. The problem with Integers is that the naive method for creating them, using the standard data types, is that when we try to decrement a positive number (or vice versa) we have to ensure that we just remove one of the increment/decrement symbols. Rather than just add a new one.
Heres the Datatype, you’ll note its similarity to Nat.
data ZZ = Pre ZZ -- decrement an integer | Z -- Zero is an integer | Suc ZZ -- increment an integer
Note that all we really did was relax the “0 is the successor of no number” axiom. Much of mathematics is discovered by this method of removing the restrictions imposed by some axiom, or assuming an axioms converse/inverse, etc. The most popular example is that of Geometry, for many years, Euclidean Geometry was all there was. However, in the 19th century, Janos Bolyai and Nikolai Ivanovich Lobachesevky (the same mathematician of Tom Lehrer’s “Lobachevsky”) independently published papers about Hyperbolic Geometry, which changed the infamous “parallel” postulate of Euclidean Geometry to say that, instead of only one line, that there are two lines which pass through a point P not on a line L that do not intersect L. Riemannian, or Ellipic Geometry, states that instead of two lines, that there are no lines. In fact, you can imagine an infinite number of geometries based on the number of lines that can be parallel to a given line. For more about Euclidean and Non-Euclidean Geometries, wikipedia has some very nice articles, links are at the bottom of the post.
So the real test is to create some smarter constructors than what is provided, then we already have. The first thing, really, is to note that we can, in fact, pattern match on functions, eg
> precInt :: Int -> Int -> Int> precInt (x + 1) = x
works just fine. So lets use that to create two functions, s and p, which are successor and predecessor over the Integers. We’ll start a new module for this, this should be placed in a separate .lhs file called “ZZ.lhs”
> module ZZ(ZZ(Z), s, p) where > data ZZ = P ZZ > | Z > | S ZZ > deriving (Show, Eq, Ord) -- that'll allow us to skip ahead a bit
Notice how we don’t have to deal with s(Z) or p(Z) that happens automagically for us.
> s :: ZZ -> ZZ > -- if we're incrementing a negative number, we can just eliminate a P > s (P x) = x > -- these take care of the normal cases, just like in the Nats > s x = (S x) > p :: ZZ -> ZZ > -- Now we just do p, in a similar way.> p (S x) = x> p x = (P x)
so now we can define addition, which is all we’ll define over the Integers, most of it will be the same or similar to the Naturals, and if you’d like to see it, I encourage you to try it, I’d love to see it working.
Here it is, Addition:
> addZZ :: ZZ -> ZZ -> ZZ > addZZ Z y = y> addZZ x y > | y | x == Z = y > | y == Z = x > | x | x > Z = addZZ (p(x)) (s(y))
Notably, this also defines subtraction, given the capability of negation, anyway. Hopefully you’ve enjoyed seeing the buildup from a simple concept of Z and S(x::Nat) to a powerful arithmetic. I think the next stop on my list is dealing with DFA/NFA and PDA evaluator and eventually a Regex Recognizer DFA automata, ala Thompson’s NFA, then maybe I’ll build a Turing Machine Interpreter. All plans are subject to change randomly for no reason at all, Stay Tuned!
~~Joe
Wikipedia articles about various geometry stuff.
Geometry
Euclidean Geometry
Non-Euclidean Geometry
Elliptic Geometry
Hyperbolic Geometry
EDIT: fixed some indentation errors
Peano’s Axioms Part III: Making use of Haskell’s Powerful Polymorphism
This time, we’ll be looking at making use of the polymorphic capabilties of Haskell’s type system.
In Haskell, Polymorphism is provided via type variables. That is, you may have a function
foo :: (a -> b) -> [a] -> [b]
which requires a function of any type to any other type, and a list of elements of the first type, and it returns a list of elements of the second type. Most people call this function map, though it can represent others.
So in addition to getting the functions defined in the typeclass, we get all the prelude functions with variable type signatures.
But wait- theres more. When we define certain types of functions, we often want to limit the scope of the function to only operate on certain variables. Like defining an instance of an interface in Java, we can specify a “scope” (though thats an abuse of the term) for a type variable. As in the following:
foo2 :: Ord a => a -> a -> a
Here, we state that a must be an instance of the typeclass Ord (and by inheritance, an instance of Eq too.) So now we know that foo2 takes two comparable elements and returns a comparable element.
Polymorphism is nothing new to any language. However, I think that Haskell really has an advantage not in the area of semantics, which are pretty much uniform — at least in the case of polymorphism. I think that Haskell’s advantage is in the syntax of polymorphism. Type signatures are easily wonderfully simple ways to express polymorphism. Both this basic kind of polymorphism (called rank-1 polymorphism), as well as higher order polymorphism (rank-2, rank-3, rank-n).
The point of this post is to show the rich library of polymorphic functions which become available with just a few (I think we’re up to 7, one derived, 6 implemented) type classes. This, as always, is a literate file, just cut and paste to a .lhs and run
$> ghci .lhs
> module Peano2 (Nat(..)) where
> import Peano
> import Data.Ratio
==============================================================
Continuing on which defining math in terms of Peano’s axioms
==============================================================
Last time I noted that we’d be working on exp, div, mod, and some other
higher-level functions. I also mentioned that we “sortof” got exp for free, in
that
S(S(S(Z)))^k,
where k is an integer, works fine, but what if we k be a natural. we’ll notice
readily that this will fail, with the error that theres no instance of
Integral Nat.
Why is that a problem? because (^) isn’t in Num, its defined elsewhere, its
signature is
(^) :: (Num a, Integral b) => a -> b -> a
Okay, so now what we should do is define Nat to be an Integral Type. So, lets go
for it.
=======================================
so, for Integral, we need quot, rem, and toInteger. We have the last of these, from the last time. Its quot and rem that we need. So, how do we define these?
well, we know that quot and rem are (effectively) just mod and div, in fact, not having negative numbers means that they are exactly the same. Lets then realize that mod is just repeated subtraction until we hit modulus > remnant. further, we relize that div is just the same, but the count of times we subtracted till we met that condition.
> quotNat :: Nat -> Nat -> Nat
> quotNat k m
> | k == m = 1
> | k < m = 0
> | otherwise = 1 + (quotNat (k-m) m)
> remNat :: Nat -> Nat -> Nat
> remNat k m
> | k == m = 0
> | k < m = k
> | otherwise = remNat (k-m) m
> quotRemNat :: Nat -> Nat -> (Nat, Nat)
> quotRemNat k m = ((quotNat k m), (remNat k m))
now, we just instantiate integral
> instance Integral Nat where
> toInteger = ntoi
> quotRem = quotRemNat
> -- this fixes a problem that arises from Nats not having
> -- negative numbers defined.
> divMod = quotRemNat
=======================================
but now we need to instantiate Enum and Real, oh my. Lets go for Enum first.
Enum requires just toEnum and fromEnum, thats pretty easy, to and from enum are just to and from Integer, which we have.
> instance Enum Nat where
> toEnum = integerToNat
> fromEnum = natToInteger
Real is actually relatively easy, we’re just projecting into a superset of the
Naturals, notably, the Rationals, so we do this simply by pushing the value
into a ratio of itself to 1, that is
toRational S(S(S(S(Z)))) ==> S(S(S(S(Z)))) % 1
> instance Real Nat where
> toRational k = (ntoi k) % 1
=======================================
Next time, we’ll go for primes.
oh- and by the way, pushing Nat into Integral gave us lots of neat things, notably even/odd, gcd/lcm, the ability to do ranges like [(Z)..], and all the appropriate functions that go with that.
So far, I’ve spent about 1 hour making all this work, you can imagine how this speed could be useful if you have defined your problem as having certain properties. Type classes are an extremely powerful tool, which can help make your code both clean, as well as powerful. In one hour, I’ve managed to build up a simple bit of code, based on some fairly primitive axioms, and create a huge amount of powerful math around it.
Imagine if you could define these same relations around data? What if you were able to define strings as having properties of numbers, heres an Idea:
Imagine you have some strings, you can define the gcd of two strings as the least common substring of two strings. If you can sensically define the product of two strings, then you can get a concept of lcm as well. Granted, the may not be the best example. But you can just imagine the power you can push into your data by defining an arithmetic, (not even an algebra!) on them. Imagine creating an arithmetic of music (been done, sortof, check out Haskore) or pictures? I use
arithmetic,because what I’m implementing here is only a little peice of the power you can instill. _This_ is why Haskell is powerful. Not because its purely functional, not even because its lazy. It’s the _math_ that makes Haskell capable of doing this. The type theory upon which Haskell rests makes Haskell powerful.
Remember, next time, Primes and Totients and Number Theory, and a datatype
representing the Integers,
Oh my!
Intermezzo: Mental Vomit.
Phew, it’s been a long few days, I have the last few posts in the Peano series coming up, and I’ve been planning out a new series of posts about a project I’ve been toying with- a Haskore-esque Music system. By the looks of it, Haskore is no longer being mantained, so maybe someday I’ll this project will actually turn into something useful, but really- I’m just looking to do something nifty with Haskell.
Today, though, I’m just going to brain-vomit and talk about some random thoughts I had.
Programming the Universe, by Seth Lloyd.
Excellent book, I’m about halfway through it. It’s really brilliantly written, very engaging, though its occasionally a little too conversational for my tastes. It’s also relatively thin, which is good, because it makes me feel proud to say I’m halfway through in less than 3 days, even though halfway through is 100 pages. It’s also kind of unfortunate, as I’ll be done with it soon, though I suppose if you have to have some problem, not wanting the book to end because your enjoying it to much is probably a good one to have. The book, principly, is about how the universe can be described as a giant quantum computer, it goes into information theory and its relation to thermodynamics and entropy. It talks about Quantum Logical Operations, though (at least up till now) not in any real detail, althoug h I saw some Bra-ket notation in later chapters. I’m not very knowledgable about Quantum Computing in general, so I hope to pick up some basic understanding from this, or at least enough language so I know where to look for more info. I figure, in 10 years, this technology will be relatively grown up, and I’ll need to know it to stay current. Might as well start now.
I am a Strange Loop, by Douglas Hofstadter
I’m a Hofstadter fanboy, I’ll admit it. GEB is the best book ever. Metamagical Themas is the second best book, and hopefully, this will be the third best. I didn’t even read the back cover when I bought this, I saw “Hofstadter” and I actually squealed a little. Yes, I squealed, but honestly, DH is quite possibly my favorite non-fiction writer ever. I’m allowed to be a fanboy. It was a manly squeal. Shut up. 😛
I haven’t started reading it yet, but my first impression (from my random flipopen to one of the pages) is that it’ll be a entertaining read, to say the least. I opened to a section headed with “Is W one letter or two?” I think it’ll be good, and the cover art is really quite nice.
Reinventing the Wheel, and why It’s a good thing.
Now a little more on topic. I’ve been hearing more and more, or maybe I’m just noticing that people say this more and more, that we — as programmers, mathematicians, etc — should not try to reinvent the wheel. For the most part, I agree. Some problems are solved, but should we discourage people from reinventing the wheel entirely? I think there is something to be said for reinventing the wheel every now and again, especially for new programmers. For instance, the recent posts about Peano’s Axioms. This has probably been done to death by other Haskeller’s out there, but why do I do it now? Partially because it shows the wonders of type classes, but also because the exercise of solving this already solved problem is an excellent way to learn about how the solution works, and furthermore how to apply those concepts to other problems. I mean, maybe I’m just ranting, but don’t we reinvent the wheel over and over? Insertion sort is a perfectly good sorting algorithm, it does the job, heck, it even does it far quicker than we could. However, if it weren’t for the fact that someone sat down and said, “Maybe this wheel isn’t as great as it could be” and reinvented it, and came up with quicksort, or radix sort, or count sort, then where would our applications be? Even looking at the actual wheel, how many times has it been reinvented? It started out as some big stone, then it was probably wood, then wood with metal plating, then mostly metal, now its a complex part with alloys and rubber and all sorts of different materials. I m guess what I’m trying to say is maybe instead of “never reinventing the wheel” we should, “Never reinvent the wheel, except in cases where reinventing the wheel would give us a better solution.” I suppose its the logical resolution to the problem presented from trying to combine this adage with the adage:
“Never say never, ever again.”
Anyway, It’s time to get back to procrastinating, or not, I guess I’ll do it later.
Peano’s Axioms Part II: Orderability and Code
So, lets get started with this Peano arithmetic stuff. For those who do not know what Peano’s axioms are, heres a brief explaination.
Peano’s Axioms define a formal system for deriving arithmetic operations and procedures over the set of “Natural” numbers. Peanos Axiom’s are most often stated as follows, though variants do exist.
1) 0 is a natural number. (Base Case)
2) If x is a natural number, S x is a natural number (Successor)
3) There is no number S x = 0 (0 is the successor of no number)
4a) 0 is only equal to 0.
4b) Two natural numbers Sx and Sy are equal iff x and y are equal.
4c) If x,y are natural numbers, then either (x == y /\ y == x) or (x /= y /\ y /= x)
5) If you have a subset K, and 0 is in K. Then if some Proposition P holds for 0, and Sx for all x in K, then K contains the naturals. (Induction, from Wikipedia)
(see Peano’s Axioms Wikipedia Entry)
The goal of this post is to define Equality, Orderability, and basic arithmetic over the Naturals. We’ll also see how the standard Peano numbers. Lets talk about Orderability, for a second.
Equality is provided for by the axioms, but what is orderability? When we think about something being ordered, we can think about a “total” ordering, or a “partial” ordering. A Total Ordering is one that satisfies the following conditions.
For some Binary relation R(x,y), (notated xRy),
1) R is antisymmetric:
(xRy /\ yRx) iff (x==y), where == is equality.
2) R is transitive:
if (aRb /\ bRc) then (aRc)
3) and R is total:
(xRy \/ yRx)
a partial order only lacks in the third axiom. What does all this mean though? Well, axiom 1 gives us an important link to equality. We can actually use this fact to either define Equality from Orderability, or vice versa. Also, Axiom 1 gives us the ability to make the MRD for the Ord class very succint, only requiring (<=) at the very least. In Haskell, the Ord class is a subclass of Eq, so we need to define equality first in Haskell. This is not a problem, as we can always use Axiom 1 to define an equality function retroactively. That is, define (<=) as a function external to the type class, over the naturals. Then define (==) as ((x<=y)&&(y<=x)). We can then instance the both classes together. Axiom 2 is pretty self explainatory, it allows us to infer an ordering of two elements from two separate orderings. One neat thing this does, that not many people point out, is this is the axiom that allows for the concept of sorting. Since effectively, when we sort, we want to chain orderings together so we can have a list with elements of the type with the property of: k_1 <= k_2 &&amp; k_2 <= k_3 && … && k_(n-1) k_1 <= k_n that is, element 1 is less than element 2, and so on, such that the first element of the list is ordered with the last. It’s relatively trivial to realize, so much so that most people don’t even bother to mention it, but it certainly is interesting to see. Axiom 3 is the defining feature of total orderings, it’s similar to the law of the excluded middle. We can see how certain relations are non-total, take for instance the relation (<). That is, the relation x
> {-# OPTIONS -fglasgow-exts #-}
> module Peano (Nat(..), one, p,
>   iton, ntoi, natToInteger,
>   integerToNat) where
=============================================
Defining Arithmetic based on Peano’s Axioms
=============================================
===============================================================================
First, we’ll define Nat, the set of natural numbers w/ 0,
This covers Axiom 1,2, and 3.
> data Nat = Z | S Nat
>   deriving Show
This encodes the concept of Natural Numbers, we aren’t going to use Haskell’s
deriving capabilities for Eq, but Show thats fine, it’d just be
tedious.
Handy bits.
> one :: Nat
> one = (S Z)
===============================================================================
Now lets build up Eq, the Equality of two numbers, this covers Axioms
2,3,4,5,7, and 8
> instance Eq Nat where
every number is equal to itself, we only need to define it for Zero, the rest
will come w/ recursion for free.
>   Z == Z = True
No number’s successor equals zero, and the inverse is also true, zero is the
successor of no number
>   S x == Z = False -- no successor to zero
>   Z == S x = False -- zero is no number's successor
Two numbers are equal iff there successors are equal, here, we state it
backwards,
>   S x == S y = (x == y)
And that, my friends, it Eq for Nat
===============================================================================
Now, lets define orderability, these two things will give us some extra power
when pushing Nat into Num.
> instance Ord Nat where
>   compare Z Z = EQ
>   compare (S x) Z = GT
>   compare Z (S x) = LT
>   compare (S x) (S y) = compare x y
Easy as pie, follows from Axioms 1,2 and 8.
===============================================================================
Now, we can push this bad boy into Num, which will give us all your basic
arithmetic functions
First, lets write (p), the magic predecessor function
> p :: Nat -> Nat
> p Z = Z -- A kludge, we're at the limit of the system here.
>   -- We'll come back to this when we start playing with ZZ
>   -- (the integers)
> p (S x) = x
=======================================
Heres (+) in terms of repeated incrementing.
> addNat :: Nat -> Nat -> Nat
First, we know that Z + Z = Z, but that will follow from the following
definitions
> addNat x Z = x
> addNat Z y = y
> addNat (S x) (S y)
>   | (S x) | otherwise = addNat y (S (S x))
=======================================
Heres (*)
> mulNat :: Nat -> Nat -> Nat
Simple, here are our rules
y’ = y
Z * Sx = Sx * Z = Z
SZ * Sx = Sx * SZ = x
Sx * y = (x) * (y+y’)
> mulNat _ Z = Z
> mulNat Z _ = Z
> mulNat a b
>   | a | otherwise = mulNat' b a a
>   where
>   mulNat' x@(S a) y orig
> | x == one = y
> | otherwise = mulNat' a (addNat orig y) orig
=======================================
We’re gonna stop and do integerToNat and natToInteger just quick.
> natToInteger :: Integral a => Nat -> a
> natToInteger Z = 0
> natToInteger (S x) = 1 + (natToInteger x)
easy enough, heres integerToNat
> integerToNat :: Integral a => a -> Nat
> integerToNat 0 = Z
> integerToNat k = S (integerToNat (k-1))
pretty nice, huh? Lets add a couple of aliases.
> iton = integerToNat
> ntoi = natToInteger
=======================================
Now we just need (-), we’ll talk about abs and signum in a second
> subNat :: Nat -> Nat -> Nat
> subNat x Z = x
> subNat Z x = Z
> subNat x y
>   | x | otherwise = subNat (p x) (p y)
=======================================
Few, after all that, we just need to define signum. abs is pointless in Nat,
because all numbers are either positive or Z,
so signum is equally easy. since nothing is less than Z, then we know the
following
> sigNat :: Nat -> Nat
> sigNat Z = Z
> sigNat (S x) = one
and abs is then just id on Nats
> absNat :: Nat -> Nat
> absNat = id
===============================================================================
After all that, we can now create an instance of Num
> instance Num Nat where
>   (+) = addNat
>   (*) = mulNat
>   (-) = subNat
>   signum = sigNat
>   abs = absNat
>   negate x = Z -- we don't _technically_ need this, but its pretty obvious
>   fromInteger = integerToNat
Phew, that was fun. Next time- we’ll play with Exp, Div and Mod, and maybe some
more fun stuff.
Quick note, pushing Peano into Num gives us (^) for free (sortof.), but we’ll
define it next time anyway
